System Design Overview
Core Principles
-
Strong Software Design Principles
- Type Safety First: Reduce the surface area of type casting with strong type guard boundaries
- Immutability by Default: Predictable state management through immutable data structures
- Composition over Inheritance: Flexible, reusable components that can be combined in various ways
- Testability: Designed with dependency injection and pure functions for easy testing
- Documentation as Code: Type definitions and inline comments serve as living documentation
-
Extensibility & Customization
- Modular architecture enabling seamless addition of new content types and features
- Plugin system for custom parsers, renderers, and data transformers
- Configuration-driven behavior allowing deep customization without code changes
- Type-safe extension points with clear interfaces and documentation
-
Content-First Architecture
- "Anything can be a page" philosophy with customizable schemas
- First-class support for rich, domain-specific content types
- Pluggable parsers and renderers for diverse content formats
This philosophy ensures Tabmark remains both powerful for power users and accessible for casual users, with a strong foundation for future innovation.
System Architecture
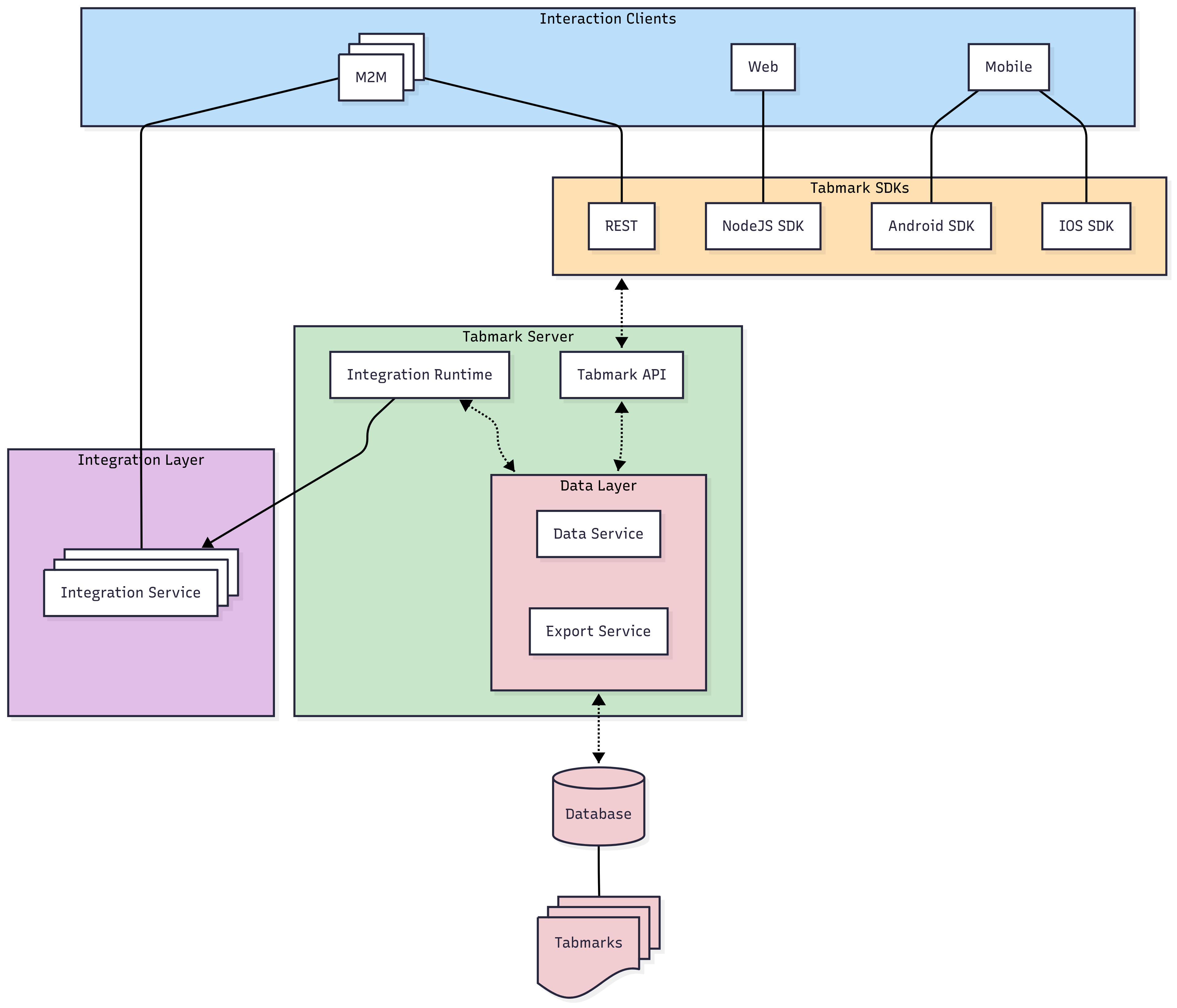
Interaction Clients
- User-facing and headless clients that interact with Tabmark data.
- Leverage Tabmark SDKs to interact with the data layer
-
Responsibilities include:
- Initiating page extraction and transformation flows.
- Displaying and editing Tabmarks.
- Triggering sync and export actions via SDK or API calls.
- UI only, no business logic.
Tabmark SDKs
- Serve as the bridge between clients and well-structured Tabmark APIs.
-
Contains the core logic for:
- Pulling raw data from the interaction client (scraping, etc.)
- Constructing Tabmarks from the raw data.
- Interacts with the data layer via Tabmark APIs.
Tabmark APIs
-
Expose authenticated, schema-consistent operations for:
- Managing Tabmarks (CRUD).
- Cloud sync and storage.
- User and device metadata.
- Export triggers and integration routing.
-
Centered around the
Tabmarktype — a structured, extensible schema representing any saved web resource. -
Backed by a centralized data store designed for:
- Cross-device availability.
- Eventual consistency and conflict resolution.
- Queryability and access control.
-
APIs are defined contract-first, driven by core TypeScript types in
packages/core, minimizing client/server drift.
Integration Layer
- Hosts pluggable adapters for interacting with external systems (e.g., Notion, Google Drive, GitHub).
-
Enables support for things like:
- Transforming Tabmarks (Tabmark → target schema).
- Lifecycle hooks.
- Authentication/session management.
- API orchestration for writes/updates.
-
Executed by the Integration Runtime — an orchestration layer designed for:
- Dependency-injected integration code.
- Deterministic, auditable side-effect execution.
- Fault tolerance and retry strategies.
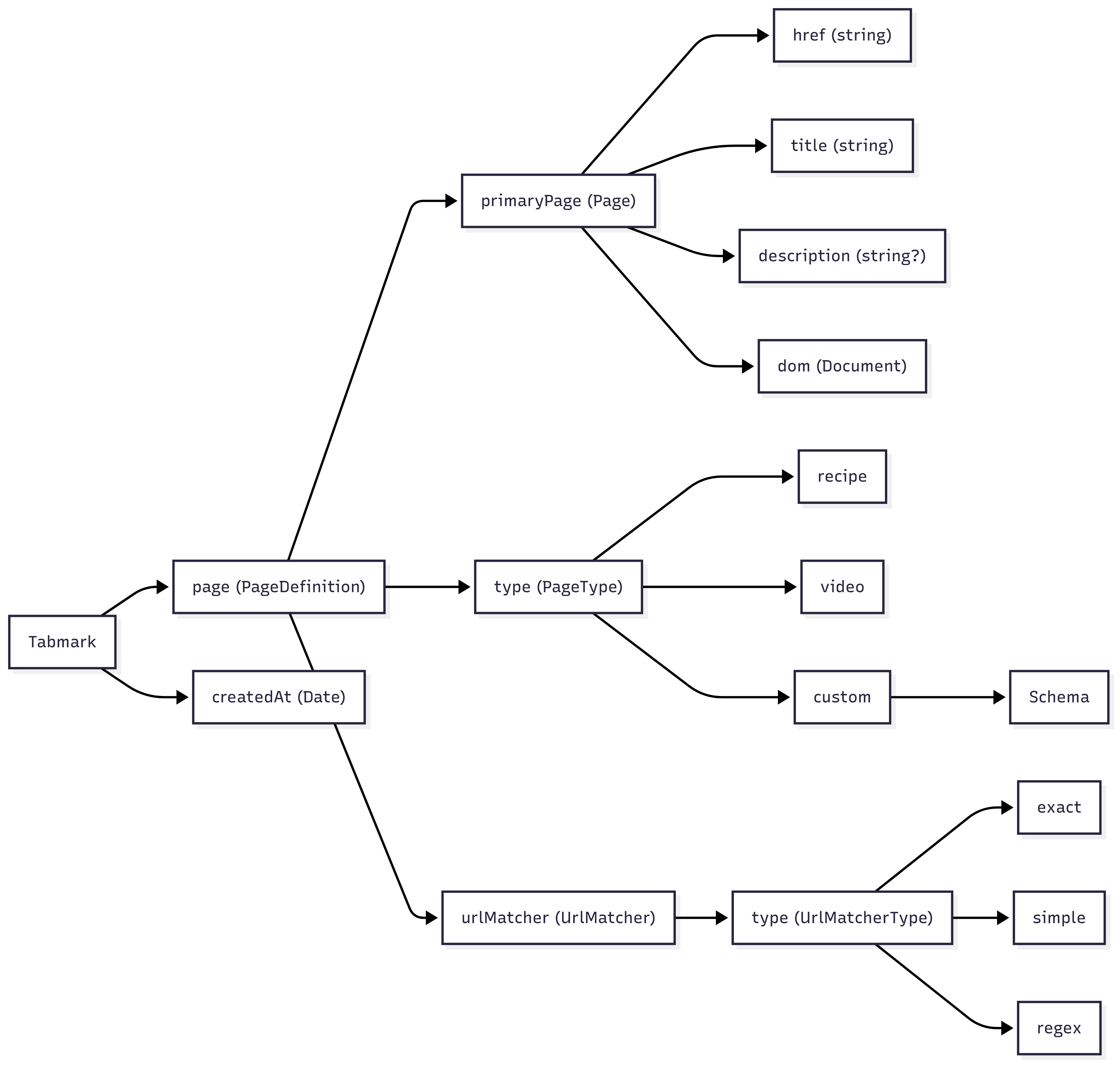
Data Model & Extensibility
At the heart of Tabmark is the canonical Tabmark data type — a structured, extensible representation of a saved web page. The system is designed with extensibility in mind; to create well-structured (and infinitly flexible) Tabmarks from anything on the web. This paves the way for advanced features like:
- Auto-discovery of page type (e.g., recipe, article, product)
- Arbitrary metadata and rendering logic anything on the internet can be a "page" with its own custom schema, parsing, transformation, rendering logic, integrations, etc.
Storage & Synchronization
- Current State: Uses local storage for persistence
- Future State: Persist the storage to a centralized location, enabling cross-device sync and integration with external services.
Future Directions
-
Enhanced Content Intelligence
- AI-powered content analysis and classification
- Smart metadata extraction and relationship mapping
- Context-aware suggestions for content organization
-
Expanded Integration
- Bidirectional sync with knowledge management platforms
- Domain-specific integrations (e.g., recipe management, research tools)
- Developer SDK for custom extensions
-
Collaboration & Sharing
- Team workspaces with fine-grained permissions
- Annotation and discussion features
- Version control for saved content
-
Advanced Discovery
- Semantic search across all saved content
- Custom views and dashboards
- Cross-content relationship visualization
Comments & Guidance
- This document is a living reference. As Tabmark evolves—across platforms, storage backends, and integrations—update this file to reflect new modules, data flows, and design decisions.
-
For contributors: Prioritize modularity, clear interfaces, and extensibility. When adding new
page types or output formats, follow the emerging
Page/Tabmarkinterface pattern. - For future maintainers: The current Chrome extension is a proof of concept. Anticipate a unified Tabmark experience across browser, mobile, and cloud.